React 两大特色之React diff
React 的两大特色:React diff 和 Virtual Dom。
前言
React diff,是 Virtual DOM和渲染的性能保证,高效的diff算法极大地保障了React的性能。使我们的页面的构建效率提到了极大的提升。
传统的diff算法
传统diff算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到 O(n^3),其中 n 是树中节点的总数。具体是怎么算出来的,可以查看知乎上的一个回答。
react的diff 从O(n^3)到 O(n) ,请问 O(n^3) 和O(n) 是怎么算出来?
懒得点链接看下:
传统Diff算法需要找到两个树的最小更新方式,所以需要[两两]对比每个叶子节点是否相同,对比就需要O(n^2)次了,再加上更新(移动、创建、删除)时需要遍历一次,所以是O(n^3)。
查找不同就需要O(n^2),找到差异后还要计算最小转换方式,最终结果为O(n^3)
1 | Prev Last |
就上面两树的变化而言,若要达到最小更新,首先要对比每个节点是否相同,也就是:
1 | PA->LA |
React的Diff算法完全不同,简单到有些粗暴,过程如下。
1 | # 按叶子节点位置比较 |
标准的O(n),所有的节点只遍历一次。
O(n^3)到O(n)的提升有多大,通过一张图来看一下
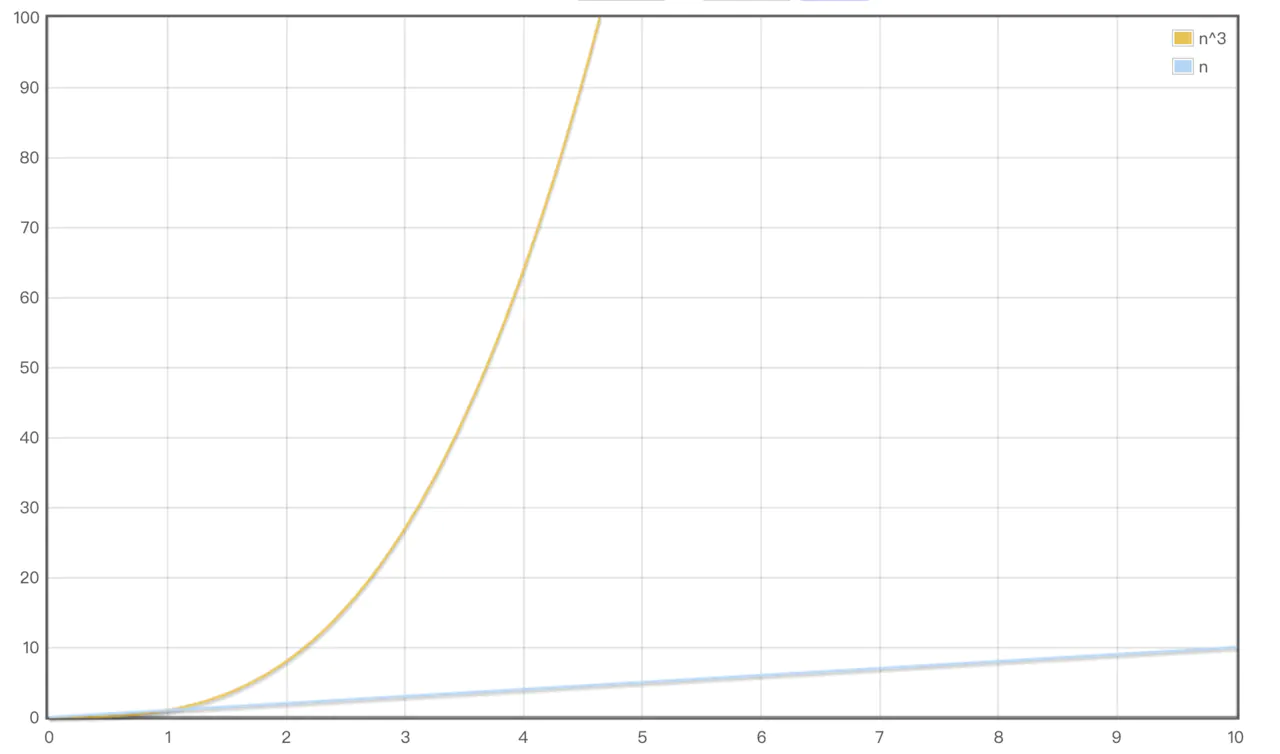
React的diff策略
策略一:忽略Web UI中DOM节点跨层级移动;(跨层级不进行比较)
策略二:拥有相同类型的两个组件产生的DOM结构也是相似的,不同类型的两个组件产生的DOM结构则不近相同(不同类不进行比较,同级节点做diff)
策略三:对于同一层级的一组子节点,通过分配唯一id进行区分(同类同级通过key比较)
上面的好像不太通俗易懂
- 一:只对同级元素进行Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会复用它。
- 二:两个不同类型的元素会产生出不同的树。如果元素由div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。
- 三:开发者可以通过 key属性 来暗示哪些子元素在不同的渲染下能保持稳定。
在Web UI的场景下,基于以上三个点,React对tree diff、component diff、element diff进行优化,将普适diff的复杂度降低到一个数量级,保证了整体UI界面的构建性能!
Tree diff
针对策略一,React对树的算法进行了优化,对树进行分层比较,两棵树只会对同一层次的节点进行比较。
既然DOM节点跨层级的移动操作少到可以忽略不计,针对这一现象,React只会对相同层级的DOM节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在时,则该节点及其子节点会被完全删除掉,不会进行下一步的比较。这样就只需要对树进行一次遍历,就能完成整个DOM树的比较。
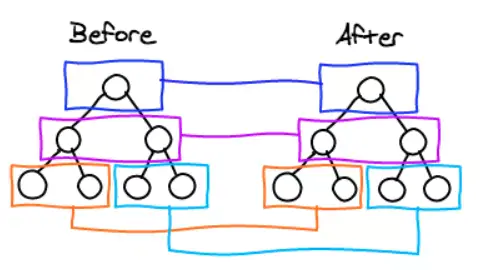
前提是WEB ui 中的DOM节点跨层级的移动操作特别少,但并没有否定DOM节点跨层级的操作的存在,那么当遇到这种操作时,React的处理方式
example; A(包括其子节点) –> D
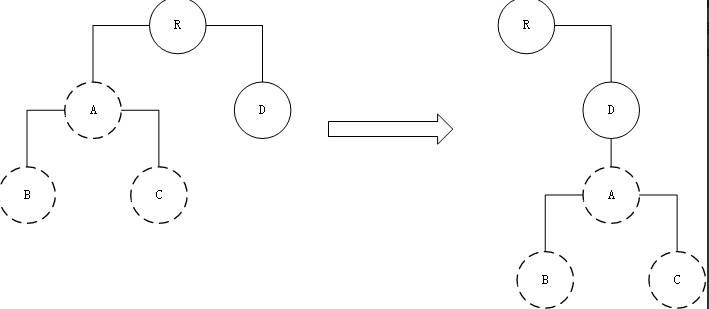
由于React只会简单的考虑同层级节点的位置变换,而对于不同层级的节点,只会创建和删除操作。当根节点发现子节点的A消失了,就会直接销毁A,当D发现多了一个子节点A,则会创建新的A(包括子节点)作为其子节点。此时,diff的执行情况是;
CreateA —> CreateB —> CreateC —> DeleteA
所以,由此可以看出,当出现节点跨层级移动,并不会出现想象中的直接把整个A节点移动到D节点下的移动操作,而是以A节点的整个树会被重新创建。so,这是一种影响React性能的操作,因此官方建议不要进行DOM节点跨层级的操作。
在开发组件时,保持稳定的 DOM 结构会有助于性能的提升。例如,可以通过 CSS 隐藏或显示节点,而不是真正地移除或添加 DOM 节点。
图整个处理过程:

Component diff
React 是基于组件构建应用的,对于组件间的比较所采取的策略也是简洁、高效的。
如果是同一类型的组件,按照原策略继续比较 Virtual DOM 树即可。
如果不是,则将该组件判定为dirty component,从而替换整个组件下的所有子节点
对于同一类型的组件,有可能其Virtual DOM没有任何变化,如果能够确切知道这点,那么可以节省大量的diff运算时间,因此,React允许用户通过ShouldComponentUpdate()来判断该组件是否需要进行diff算法,但如果调用了forceUpdate方法,ShouldComponentUpdate会失效
example; D –> G
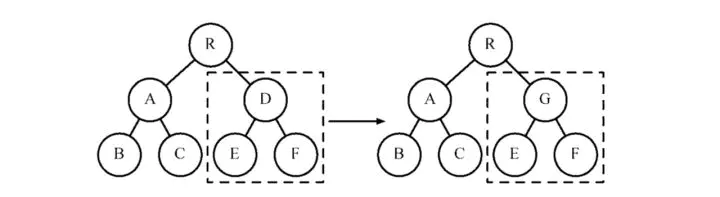
内部流程

当组件D变为组件G时,即使这两个组件的结构相似,一旦React判断D和G是不同类型的组件,就不会比较二者的结构,而是直接删除组件D,重新创建组件G及其子节点。虽然当两个组件时不同类型但结构相似时,diff会影响性能,但入React官方所说,不同类型的组件很少存在相似DOM树的情况,因此这种极端因素很难在实际开发过程中造成较大的影响。
Element diff
当节点处于同于同一层级时候,diff提供了3种节点操作,分别是插入、移动、删除
- 插入:新的组件类型不在旧集合里,即全新的节点,需要对新节点执行插入操作
- 移动:旧集合里有新组件类型,且element是可更新的类型,这种情况下 prevChild=nextChild ,就需要做移动操作,可以复用以前的 DOM 节点。
- 删除:旧组件类型,在新集合里也有,但对应的element不同则不能直接复用和更新,需要执行删除操作,或者旧组件不在新集合里,也需要执行删除操作。
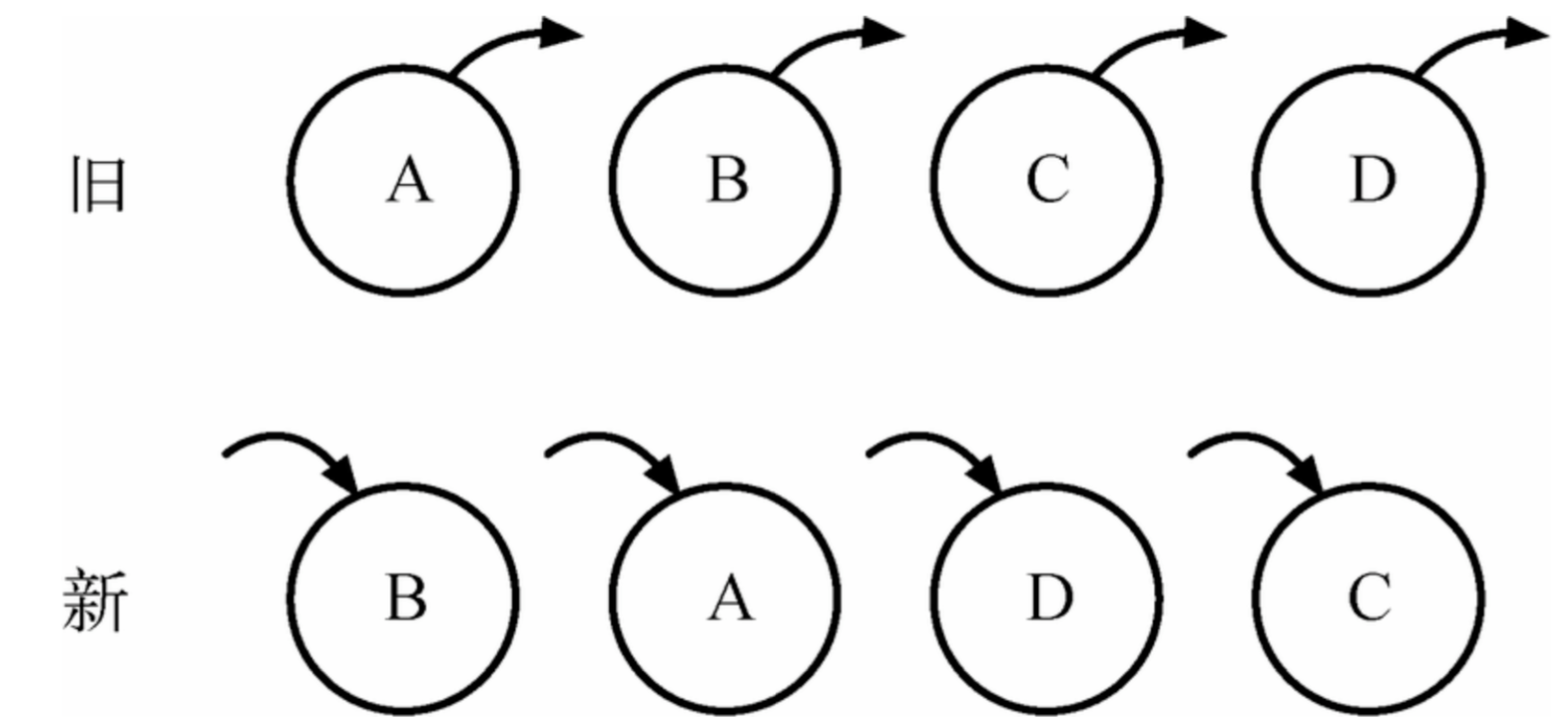
旧集合中包含节点A、B、C和D,
更新后的新集合中包含节点B、A、D和C,
此时新旧集合进行diff差异化对比,发现B!=A,则创建并插入B至新集合,删除旧集合A;以此类推,创建并插入A、D和C,删除B、C和D。
我们发现这些都是相同的节点,仅仅是位置发生了变化,但却需要进行繁杂低效的删除、创建操作,其实只要对这些节点进行位置移动即可。React针对这一现象提出了一种优化策略:让开发者对同一层级的同组子节点,添加唯一key进行区分。虽然这只是小小的改动,性能上却发生了翻天覆地的变化,再来看一下应用了这个策略之后,diff是如何处理的
example:
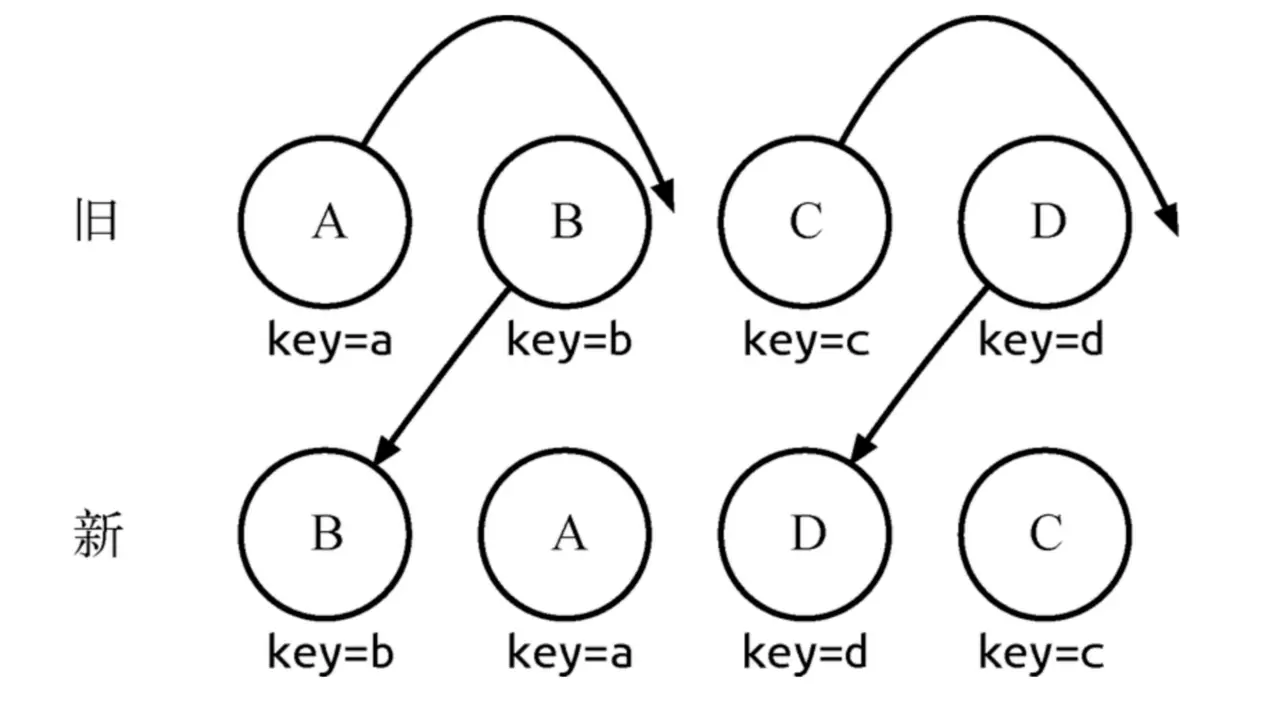
通过key可以准确的发现新旧集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将旧集合中的位置进行移动,更新为新集合中节点的位置名词是的React给出的diff结果为:B、D不做任何操作,A、C进行移动操作就行。
具体的流程看表格:
| index | 节点 | oldIndex | lastIndex | 操作 |
|---|---|---|---|---|
| 0 | B | 1 | 0 | oldIndex(1)>lastIndex(0),lastIndex=oldIndex,lastIndex变为1 |
| 1 | A | 0 | 1 | oldIndex(0)<lastIndex(1),节点A移动至index(1)的位置 |
| 2 | D | 3 | 1 | oldIndex(3)>lastIndex(1),lastIndex=oldIndex,lastIndex变为3 |
| 3 | C | 2 | 3 | oldIndex(2)<lastIndex(3),节点C移动至index(3)的位置 |
- index: 新集合的遍历下标。
- oldIndex:当前节点在老集合中的下标。
- lastIndex:在新集合访问过的节点中,其在老集合的最大下标值(在老集合中最右的位置, 即最大的位置)。
操作一栏中只比较oldIndex和lastIndex:
当oldIndex>lastIndex时,将oldIndex的值赋值给lastIndex
当oldIndex=lastIndex时,不操作
当oldIndex<lastIndex时,将当前节点移动到index的位置,
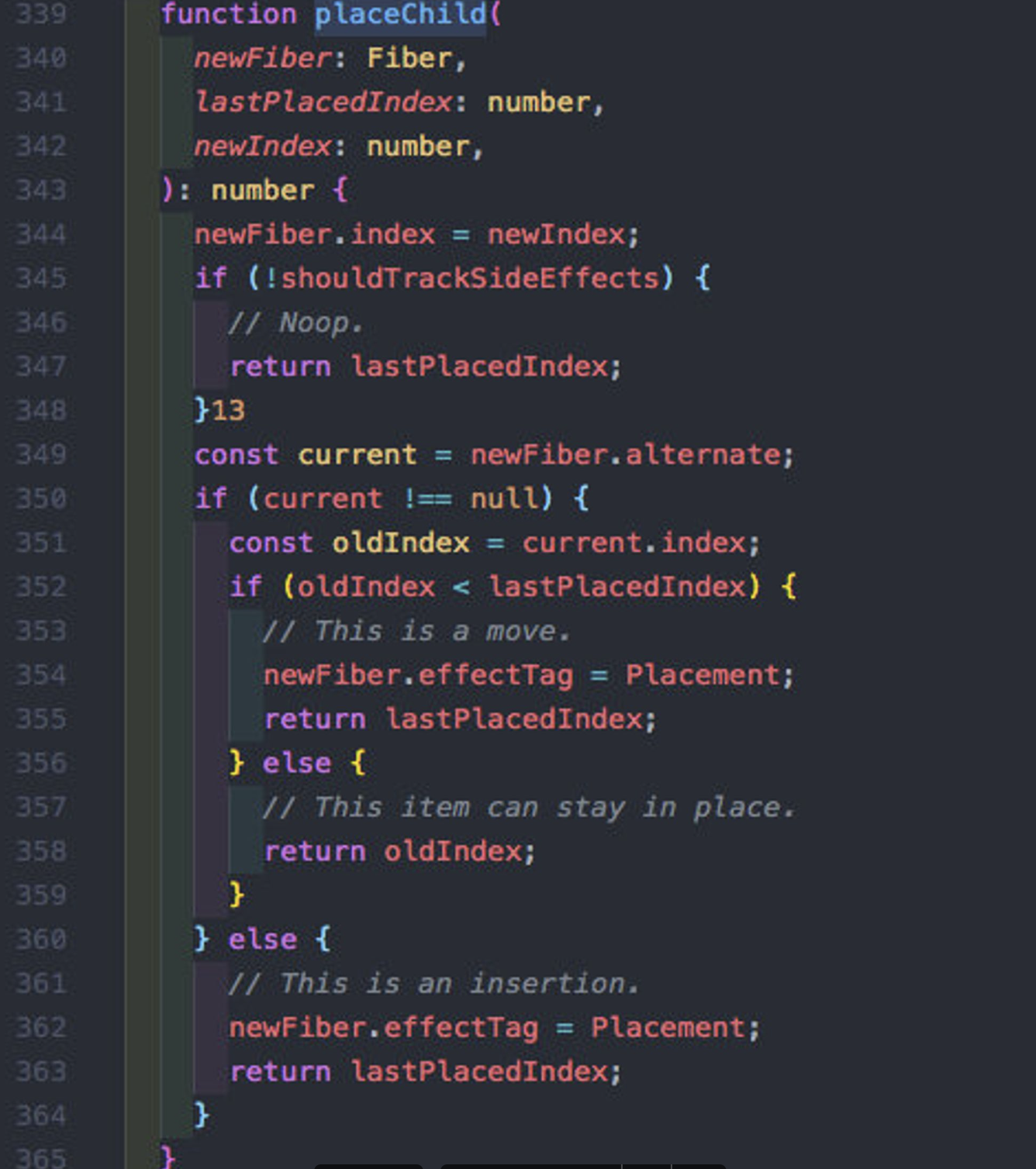
新版本React,应该是从v16起, placeChild(newFiber, lastPlacedIndex, newIndex), lastPlacedIndex就是当前的新fiber数组中已经遍历过的fiber中在上一次更新时的index中最大的那个,就是上面的lastIndex
老版本React源码中的enqueueMove(this, child._mountIndex, toIndex),其中 toIndex 其实就是 nextIndex
上面例子是新旧集合中的节点都是相同的节点的情况下,那如果新集合中有新加入的节点且旧集合存在 需要删除的节点,那么 diff 又是如何对比运作的
ABCD –> BECA
| index | 节点 | oldIndex | lastIndex | 操作 |
|---|---|---|---|---|
| 0 | B | 1 | 0 | oldIndex(1)>lastIndex(0),lastIndex=oldIndex,lastIndex变为1 |
| 1 | E | - | 1 | oldIndex不存在,添加节点E至index(1)的位置 |
| 2 | C | 2 | 1 | oldIndex(2)>lastIndex(1),lastIndex=oldIndex,lastIndex变为2 |
| 3 | A | 0 | 2 | oldIndex(0)<lastIndex(2),节点A移动至index(3)的位置 |
PS:最后还需要对旧集合进行循环遍历,找出新集合中没有的节点,此时发现存在这样的节点D,因此删除节点D,到此 diff 操作全部完成。
同样操作一栏中只比较oldIndex和lastIndex,但是oldIndex可能有不存在的情况:
- oldIndex存在
- 当oldIndex>lastIndex时,将oldIndex的值赋值给lastIndex
- 当oldIndex=lastIndex时,不操作
- 当oldIndex<lastIndex时,将当前节点移动到index的位置
oldIndex不存在
- 新增当前节点至index的位置
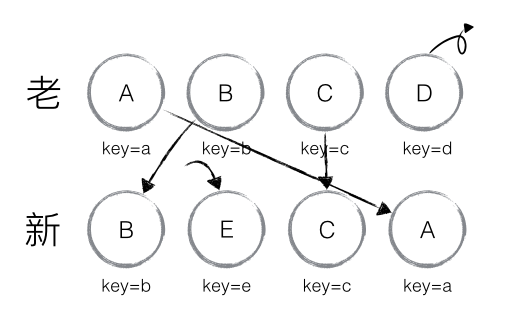
当然这种diff并非完美无缺的,我们来看这么一种情况:
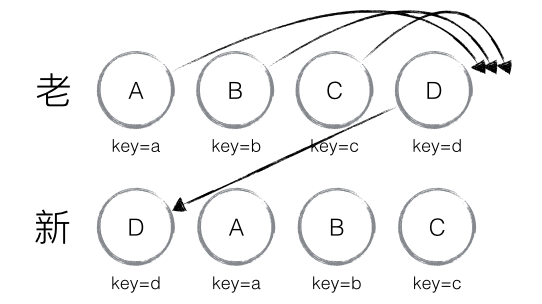
实际我们只需对D执行移动操作,然而由于D在旧集合中的位置是最大的,导致其他节点的oldIndex < lastIndex,造成D没有执行移动操作,而是A、B、C全部移动到D节点后面的现象。针对这种情况,官方建议:
在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作。当节点数量过大或更新操作过于频繁时,这在一定程度上会影响React的渲染性能
由于key的存在,react可以准确地判断出该节点在新集合中是否存在,这极大地提高了diff效率。我们在开发过中进行列表渲染的时候,若没有加key,react会抛出警告要求开发者加上key,就是为了提高diff效率。
但是加了key一定要比没加key的性能更高吗?我们再来看一个例子:
1 | 现在有一集合[1,2,3,4,5],渲染成如下的样子: |
通过上面的例子我们发现,虽然加了key提高了diff效率,但是未必一定提升了页面的性能。因此我们要注意这么一点:
对于简单列表页渲染来说,不加key要比加了key的性能更好
根据上面的情况,最后我们总结一下key的作用:
- 准确判断出当前节点是否在旧集合中
- 极大地减少遍历次数
渲染
合并操作
当调用component的setstate时,React会将其标记为dirty。到每个时间循环结束,React检查所有标记dirty的component重新绘制
这里的“合并操作”是说,在一个事件循环中,DOM只会被更新一次,这个特性是构建高性能应用的关键。
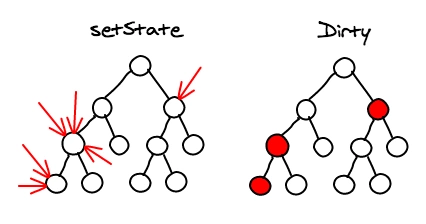
子树渲染
调用setState方法时,component会重新构建包括子树子节点的virtual DOM 。如果你在根节点调用setState,整个React应用都会被重新渲染。所有的component,即便没有更新,都会调用他们的render方法,这个听起来很可怕,性能实际上很低,但实际上我们不会触及真实的DOM,运行起来就没问题。
在写react代码时,每当数据有更新,你都不会算调用根节点的setState。你会在需要接收对应的component上调用,或者在上面的几个component。你很少要一直到根节点。就是说页面更新只出现在用户交互的部分。
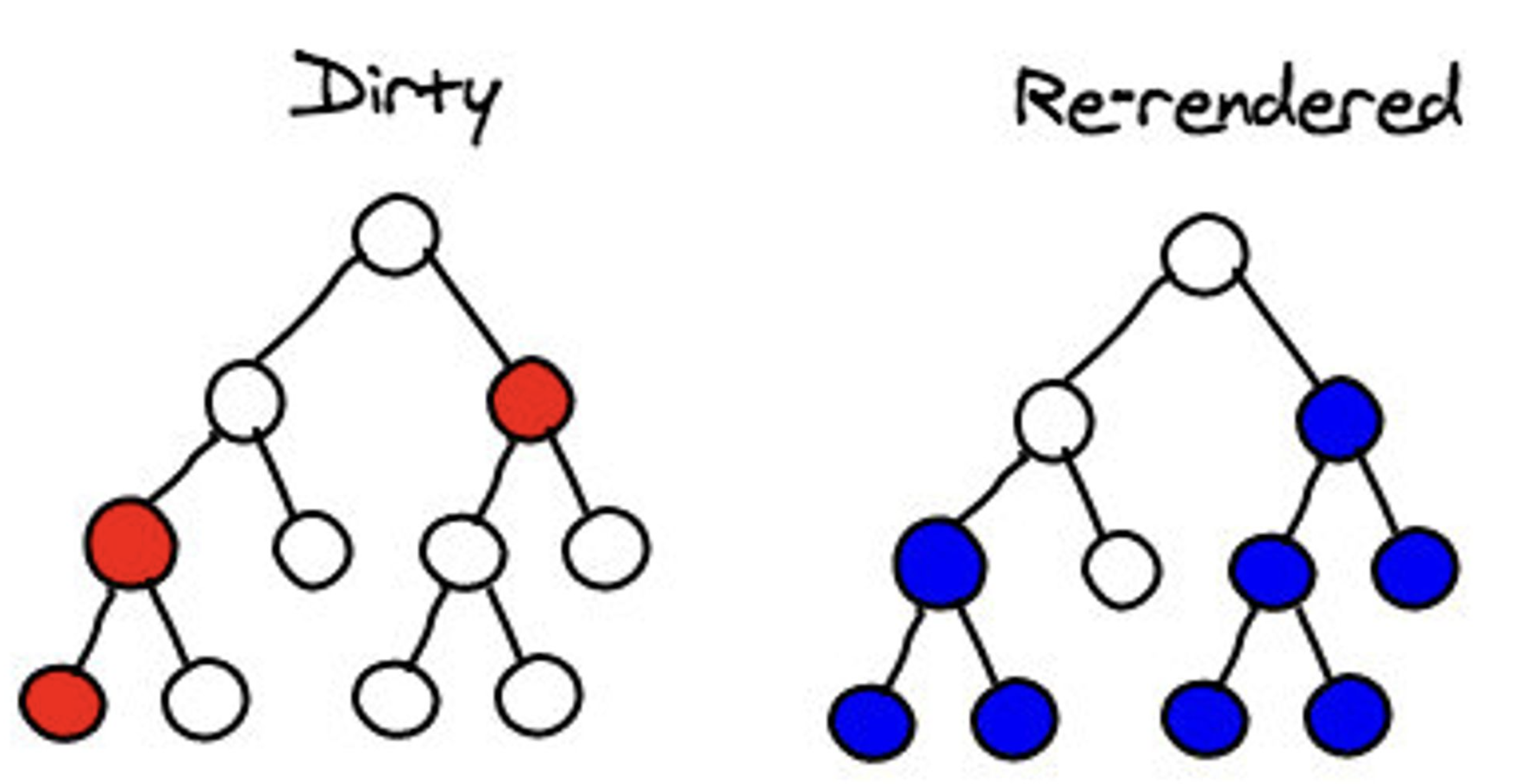
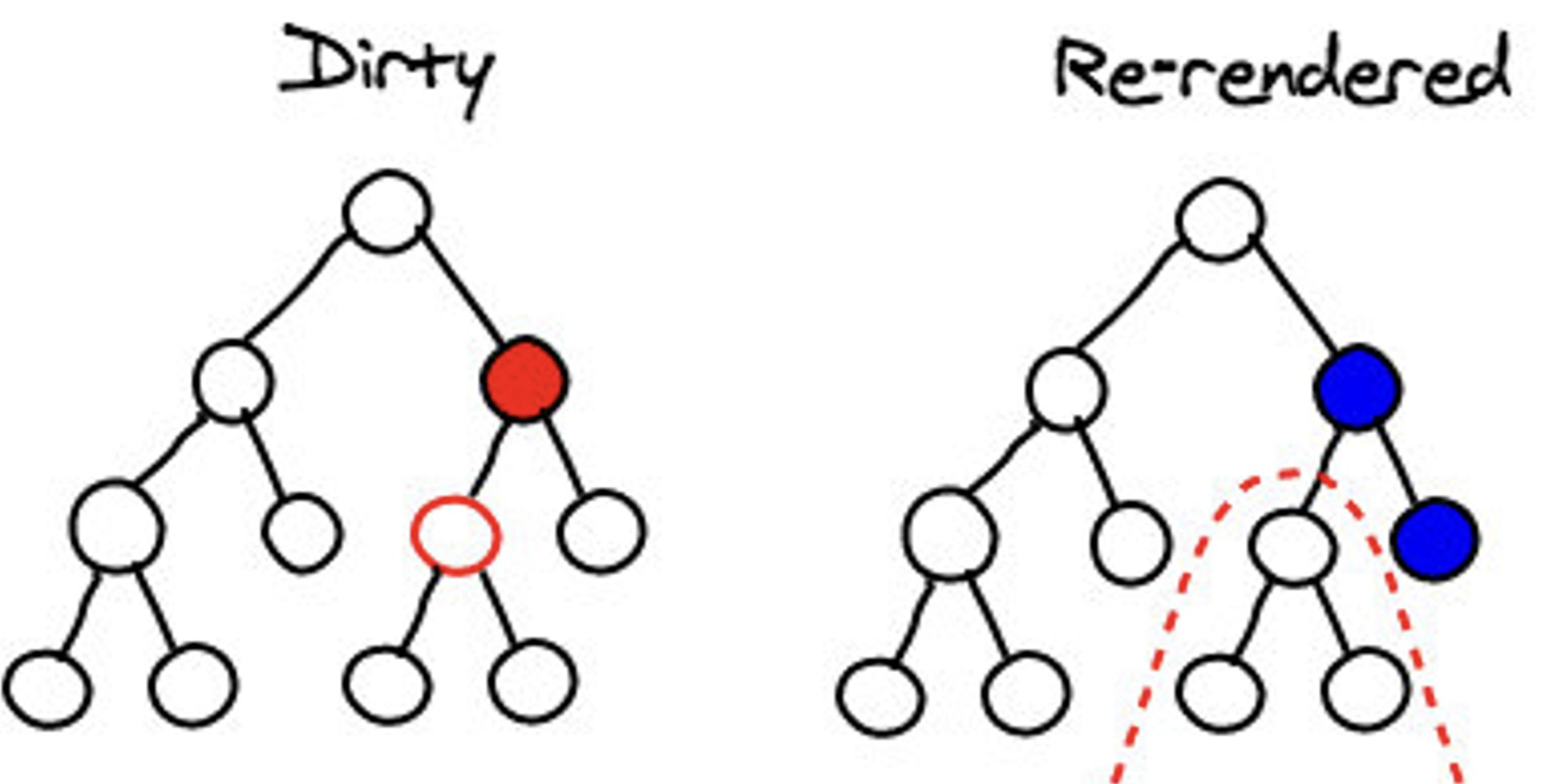
选择子树渲染
去掉一些子树的重新渲染.
1 | boolean shouldComponentUpdate(object nextProps, object nextState) |
根据component的前一个和下一个props/state, 你可以告诉React这个component没有更新,也不需要重绘
注意, 这个函数每次都会被调用, 所以你要确保运行起来花的时间更少,
比 React 的做法时间少, 还有比计算 component 需要的时间少,
即便重新绘制并不是必要的.Ps: 不过有可能你的方法里写的比React花费的时间更多
总结
React的高效得益于VIrtual DOM + React diff的体系。diff算法并非React独创,react只是在传统的diff算法中做了优化。但因为优化,将diff算法的时间复杂度一下从O(n^3) 降到了 O(n)。
开发组件时,保持稳定的dom结构会有助于性能的提升。
开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作。
key的存在是为了提升diff效率,但未必一定就可以提升性能,记住简单列表渲染情况下,不加key要比加key的性能更好。(不过可能因为React console的提醒,大家都会加上,个人觉得这点性能问题不大)。
我们可以根据diff的特点,在具体场景中取长补短,规避一些算法上面的短板也是有利于提升应用整体的性能。
之后可以简单实现下diff
参考
react的diff 从O(n^3)到 O(n) ,请问 O(n^3) 和O(n) 是怎么算出来?

